Saitoh lab
Kyushu Institute of Technology
SSSD: Speech Scene by Smart Device
What is SSSD?
The speaker uses the in-camera of the smart device to record the utterance scenes by the speaker. The speaker took the speech scene by putting the smart device on the desk, or holding the smart device in his/her hand. Many scenes were taken in university laboratory room or apartment room, however there are also scenes recorded in the car. There is no restriction on the sound or silent during the recording.
News
- May 22, 2018: Released 5,000 test data for the competition 'Lip Reading Challenge' (5th Silent Speech Recognition Workshop).
- April 8, 2018: Released our database.
- Speaker: 36
- Utterance: 25 words
- Language: Japanese
- Available data
- Lower face image (image size: 300x300[pixel])
- Feature points
- Device: Smart devices, such as Apple iPad Pro and smartphones
- Frame rate: 30fps
- Released datte: March xx, 2018
Details of SSSD
- Utterance content: Japanese 25 words
# Utterance # Utterance # Utterance 0 /ze-ro/ 10 /a-ri-ga-to-u/ 20 /do-u-i-ta-shi-ma-shi-te/ 1 /i-chi/ 11 /i-i-e/ 21 /ha-i/ 2 /ni/ 12 /o-ha-yo-u/ 22 /ha-ji-me-ma-shi-te/ 3 /sa-N/ 13 /o-me-de-to-u/ 23 /ma-ta-ne/ 4 /yo-N/ 14 /o-ya-su-mi/ 24 /mo-shi-mo-shi/ 5 /go/ 15 /go-me-N-na-sa-i/ 6 /ro-ku/ 16 /ko-N-ni-chi-wa/ 7 /na-na/ 17 /ko-N-ba-N-wa/ 8 /ha-chi/ 18 /sa-yo-u-na-ra/ 9 /kyu/ 19 /su-mi-ma-se-N/
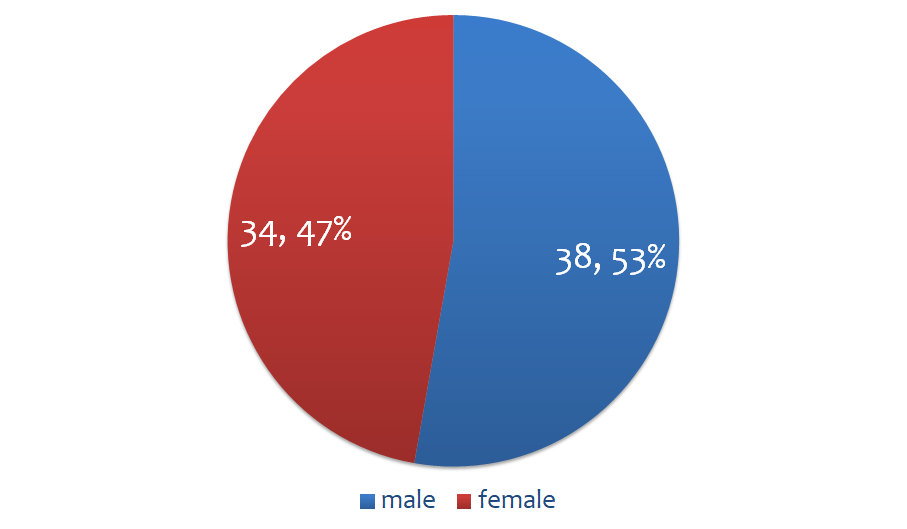
- Number of speaker: 36 (21 males and 15 females)
- Gender distribution
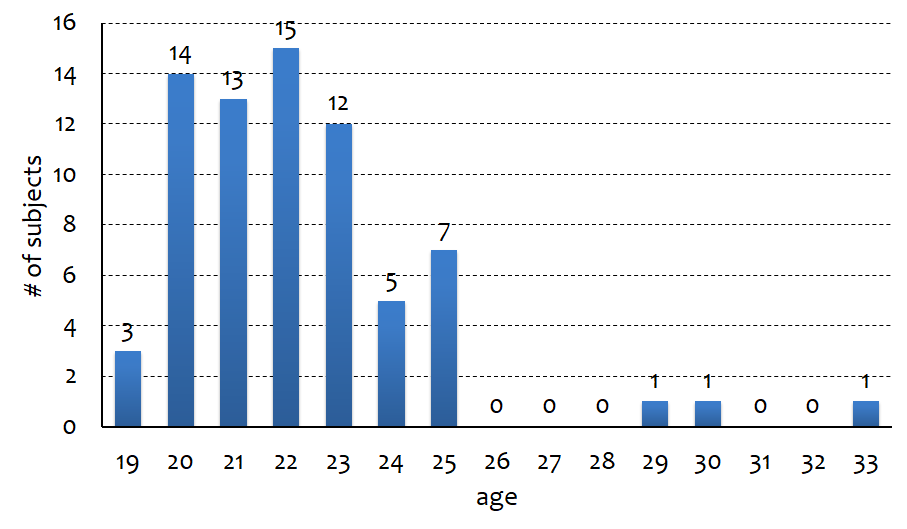
- Age distribution
All speakers are university students.
- Gender distribution
- Available data
- 36 subjects (21M + 15F) x 25 words x 30 samples = 27,000 samples
- Lower half face ROI (LF-ROI) images (image size : 300 x 300 [pixels], jpeg-format)
Frame images are stored in folder at each utterance sample.
All 750 samples of each speaker are compressed in zip-format. Each file size of zip-file is approximately 800 MB, 28.7 GB for 36 speakers.
The figure below is released LR-ROIs of 36 speakers.

Sample: s10_001_001.zip (approx. 640 kB) An utterance sample of word #1 of speaker s10. - Facial feature points (70 points, csv-format)
All 750 samples of each speaker are compressed in zip-format. Each file size of zip-file is approx. 5.7 MB, 200 MB for 36 speakers.
Sample: s10_001_001.csv (approx. 16 kB) An utterance sample of word #1 of speaker s10. - Audio data: none
- Relationship between LF-ROI and feature points
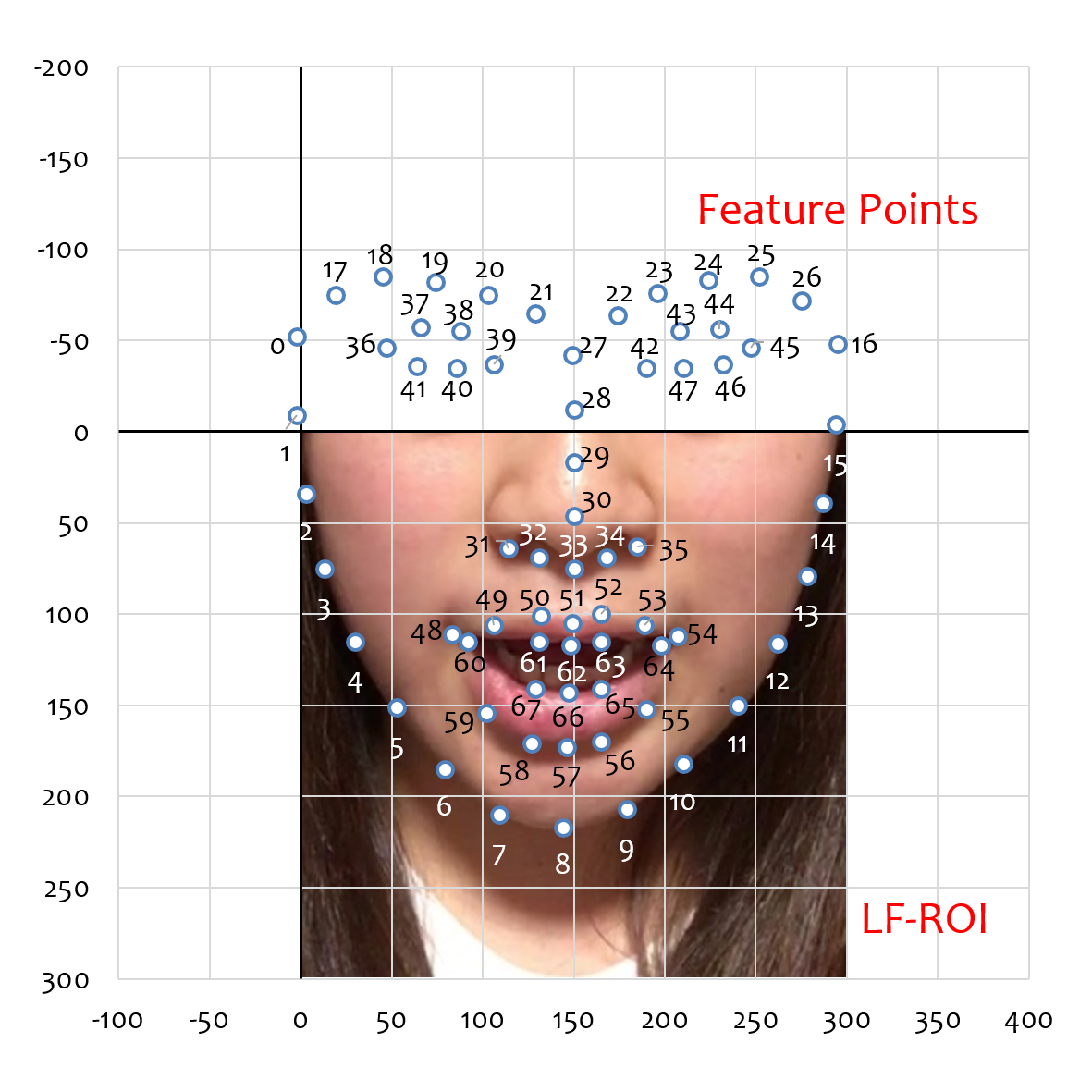
* This is a different sample from s10_001_001. - Preprocessing (how to extract LF-ROI): Please refer [1].
- Training data and test data of [1]
- * Training data (24 speakers): List of LF-ROI folders, list of csv-files
- * Test data (12 speakers): List of LF-ROI folders, list of csv-files
- Note: In the list file, the csv-file name (or LF-ROI folder name) is written in the first column, and the correct word number is written in the second column.
- Other: The provided data is as of April 8, 2018. In the future, the contents of the provided data may change.
- 36 subjects (21M + 15F) x 25 words x 30 samples = 27,000 samples
- Devices: Smart device (Apple iPad Pro, and various smartphones)
- Frame rate: 30 fps
- Limitation: Only use tge database for academic research. The user may not distribute the database or portions thereof in any way.
- Release data: April 8, 2018
- Price: free
- Distribution: If you want to get this database, please contact to the following address.
E-mail: saitoh at ces.kyutech.ac.jp - Publications:
- [1] Takeshi Saitoh, Michiko Kubokawa: SSSD: Speech Scene Database by Smart Device for Visual Speech Recognition, Proc. of ICPR2018, pp.3228-3232, 2018.
- Contact:
Kyushu Institute of Technology
Takeshi Saitoh
E-mail: saitoh at ai.kyutech.ac.jp - This project has been supported by JSPS KAKENHI Grant Number 16H03211 and the Program for Building Regional Innovation Ecosystems.